Solution Overview
What is it? The Gen AI Software template is an AWS App that can be deployed on top of the AWS Gen AI Environment Provider. It is a sample implementation of how we can deploy applications with common Gen AI use cases via Harmonix on AWS. The solution leverages RAG (Retrieval-Augmented Generation), an AI framework used to retrieve facts from an external knowledge base to ground large language models (LLMs), to create a Chatbot.
Why was it made? With the rise of Generative AI, customers have become increasingly interested in how they can implement it into their own use cases. For companies considering adopting an IDP, this software template provides a reference for how they can leverage an IDP to deploy modern AI solutions.
Who is it for? This solution is primarily aimed at Data Scientists. This solution will deploy all of the infrastructure and logic (see architecture) to support a Generative AI Chatbot. Customizations to this template are created in the form of parameters that can be set by the Data Scientist to fine tune their model. And while this solution is aimed at Data Scientists, please note that it is a reference implementation, and can be modified by Application Developers to customize the solution to meet their business needs.
Architecture
The Gen AI Application Software Template will deploy the following resources:
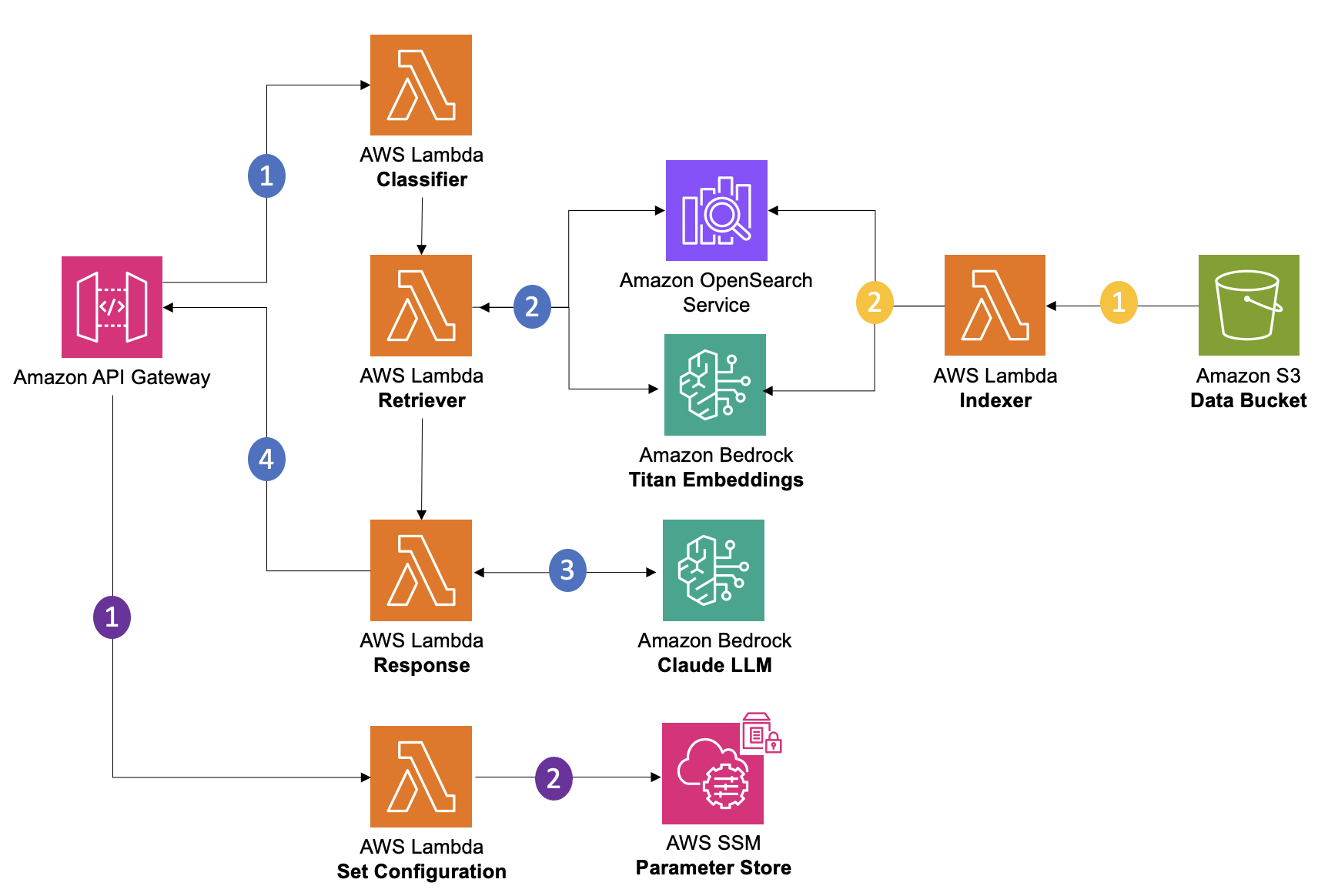
The solution contains 3 main processes:
I. Set Configuration (purple) - sets the parameters to hypertune the model
- Application Developer makes API call to the /setConfiguration method in Amazon API Gateway with their specified parameters. Sample request bodies and defined parameters can be found in the
./eventsfolder of your application's source code repository. - This will call the Set Configuration Lambda that will take in the updated parameters and store them in AWS SSM Parameter Store to be referenced in other Lambda Functions throughout the solution.
II. Document Upload and Embedding (yellow) - adds context to the LLM
- Application Developer uploads contextual files to Amazon S3.
- Amazon S3 triggers the Indexer Lambda that will call the Amazon Bedrock Titan Embedding Model and store the embeddings of that file in Amazon OpenSearch Service.
III. ChatBot (blue)
-
End User makes an API request to the /classification method in Amazon API Gateway. Sample request bodies can be found in the
./eventsfolder of your application's source code repository. -
The Classifier Lambda will take the question passed by the user and extract the keyword that matches the indices created by the Index Lambda. The response of this lambda will be a JSON with the question and the index extracted from it and passed to the Retriever Lambda.
-
The Retriever Lambda takes in the request (user’s questions and index). This index is used to retrieve the relevant document embeddings from Amazon OpenSearch Service Serverless. The response of this lambda will be the user’s questions and all the content of the relevant documents, this will pass as a request for the Response Lambda.
-
The final part of the process is in the Response Lambda, where the request will pass to Amazon Bedrock - Claude LLM. The model will take the content of the documents and the question, analyze them and come up with an answer based on the documents.
-
The final answer is formatted and sent as a response back to the end user.